Debugging an Empty Spam Email
Despite the best efforts of modern spam filters, we all still receive spam once in a while. When I see a spam email pop up in my main inbox, I often wonder what magic the spammer has discovered that allowed them to bypass Gmail’s spam filtering. (Often times, this translates into me being much more suspicious of a spam email than usual, as it must be “more advanced” in some way to have landed in my inbox.)
Just this past week, I received one such email. It had no subject, no body, was addressed to no one, but was cc’d to myself and 29 other Peters.
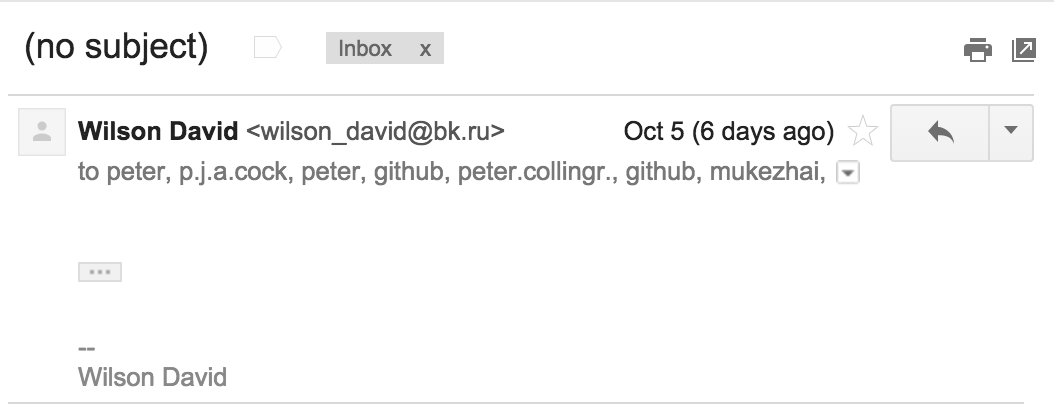
(The “…” box provided by Gmail did not expand or collapse any content when clicked.)
A side note on the recipients - it looks like the other unlucky email addresses either contained the string “peter” in the local part or the domain part. Interestingly, some of the recipients’ addresses did not contain the string “peter,” but visiting their domains revealed that they belonged to people named Peter. I suspect some other metadata was involved in choosing this list.
The return path of the email was a free account at a Russian webmail provider, bk.ru. It’s hard to tell if the spammer owns this email address, or compromised its credentials and is using it to send out spam, but I’m guessing the latter is true.
This email confused me for a few reasons. Why would a spammer waste time sending out an empty email? What’s the point of a spam email that has no content? To dig deeper into what’s in this email (and it’s not empty, that’s for sure) we’re going to have to look at the raw email body itself. Gmail provides access to the raw message body with the “Show original” option in its drop-down menu:

Clicking on “Show original” will show a summary of the original message, as well as the original message body itself:

If you’re not familiar with raw email message bodies, they’re not unlike HTTP requests. They start with headers, one header per line (with header names separated from values by colons). The end of the headers is indicated by a double-newline (“\n\n”, or “\r\n\r\n” depending on character encoding). These headers contain everything from the sender’s email address to the recipients, to the servers in between that received and forwarded messages. Of particular importance, though, is the Content-Type header:
Content-Type: multipart/alternative; boundary="--ALT--FP504ntv5azlR7xUQktA3MxnXkgct5eW1475692425"
As in HTTP, this header denotes the MIME type of the content. This email, like most nowadays, is a multipart email (as defined by RFC 1341), which means it can contain multiple distinct parts. The multipart/alternative type is a particular kind of multipart message that specifies its parts are semantically equivalent, but presented in different formats. This is how most HTML emails work, to preserve backwards compatibility with email clients that can’t (or are configured not to) display HTML emails. From StackOverflow:
The last entry is the best/highest priority part, so you probably want to put the
text/htmlpart as the last subpart. Per RFC 1341.
By specifying both text and HTML parts, older email clients can display the text part that they know how to render, while newer clients can display the HTML.
So is that it? Does this mysterious empty email contain multiple parts that should be semantically equivalent (i.e.: contain the same message) but aren’t? Well, kind of. The first part of the email looks like this:
----ALT--FP504ntv5azlR7xUQktA3MxnXkgct5eW1475692425
Content-Type: text/plain; charset=utf-8
Content-Transfer-Encoding: base64
CgoKLS0gCldpbHNvbiBEYXZpZA==
Note that this is a plain-text content section, but with a content-transfer-encoding of base64. We can decode the base64 string with Python:
In [49]: base64.decodestring('CgoKLS0gCldpbHNvbiBEYXZpZA==')
Out[49]: '\n\n\n-- \nWilson David'
And as it turns out, the plain text part of the email contains only the email signature. This is roughly what we’re seeing in Gmail, so one hypothesis would be that Gmail is skipping the HTML part and only displaying the text/plain part. But what about the HTML part? What’s in there?
----ALT--FP504ntv5azlR7xUQktA3MxnXkgct5eW1475692425
Content-Type: text/html; charset=utf-8
Content-Transfer-Encoding: base64
CjxIVE1MPjxCT0RZPjxicj48YnI+PGltZyBzcmM9ImRhdGE6aW1hZ2UvcG5nO2Jhc2U2NCxpVkJP...
...50,000 more bytes...
Hmm. So the email body actually contains 50kb of data, but Gmail’s only displaying a handful of bytes. Let’s run that base64-encoded string through our Python string decoder again:
In [56]: base64.decodestring(a)
Out[56]: '\n<HTML><BODY><br><br><img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAgAAAAGAC.../4DgZXPSWUmsAAAAASUVORK5CYII="><br>-- <br>Wilson David</BODY></HTML>\n'
Aha! So it’s HTML, and not very much HTML at that. In fact, there’s another base64-encoded string within the message, used to encode a data-URI for an embedded image. If we look at what Gmail renders in its DOM, we can actually see that it’s rendering the HTML part, but stripping out the src attribute from the image:
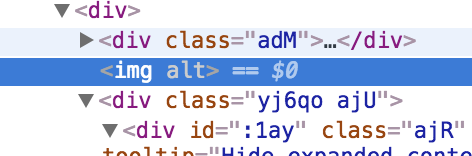
So, what’s this image? For the third time, let’s use Python to decode it:
In [38]: png = base64.decodestring(b[53:-40])
In [39]: png
Out[39]: '\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR
Well, it looks like a PNG. Many PNG decoders have been exploitable(1, 2), but I figure a fully-updated and patched Chrome should be impervious to any PNG exploits. After writing the decoded string to a file, I opened it in Chrome to find:

Success! As expected, a Togolese lawyer is offering me $9,580,000. So it looks like the email does contain some spam content - in particular, a PNG of some text. As most spam filters don’t bother doing deep inspection of image attachments (save for scanning for viruses), the text rendered in this particular image made its way through Gmail’s spam filter. However, Gmail’s failure to render the data-uri image resulted in an empty email, unexpectedly removing the spam in a different way.