The Architecture of an Infinite Stream of Music
Nearly a year ago, I launched forever.fm - a free online radio station that seamlessly beat matches its songs together into a never-ending stream. At launch, it was hugely popular - with hundreds of thousands of people tuning in. In the months since its initial spike of popularity, I’ve had a chance to revisit the app and rebuild it from the ground up for increased stability and quality.

(Grab the free iOS and Android apps to listen to forever.fm on the go.)
Initially, Forever.fm was a single-process Python app, written with the same framework I had built for my other popular web app, The Wub Machine. While this worked as a proof of concept, there were a number of issues with this model.
- Single monolithic apps are very difficult to scale. In my case, Forever.fm’s monolithic Python process had to service web requests and generate the audio to send to its listeners. This task is what’s known as a “soft real-time” task - in which any delays or missed deadlines cause noticeable degradation of experience to the user. As the usage of the app grew, it became difficult to balance the high load generated by different parts of the app in a single process. Sharding was not an option, as Forever is built around a single radio stream - only one of which should exist at the same time. Unlike a typical CRUD app, I couldn’t just deploy the same app to multiple servers and point them at at the same database.
- Single monolithic apps are very difficult to update. Any modifications to the code base of Forever required a complete restart of the server. (In my initial iteration and blog post, I detailed a method for reloading Python modules without stopping the app - but ran into so many stability issues with this method that I had to abandon it altogether.) As with any v1 app, Forever had a constant stream of updates and fixes. Restarting the app every time a bug fix had to be made - thereby stopping the stream of music - was ridiculous.
- Memory usage and CPU profiling were both difficult problems to solve with a one-process app. Although Python offers a number of included profiling tools, none of them are made to be used in a production environment - which is often the environment in which these problems occur. Tracking down which aspect of the app is eating up gigabytes of memory is critical.
To solve all of these problems in one go, I decided to re-architect Forever.fm as a streaming service-oriented architecture with a custom queueing library called pressure.
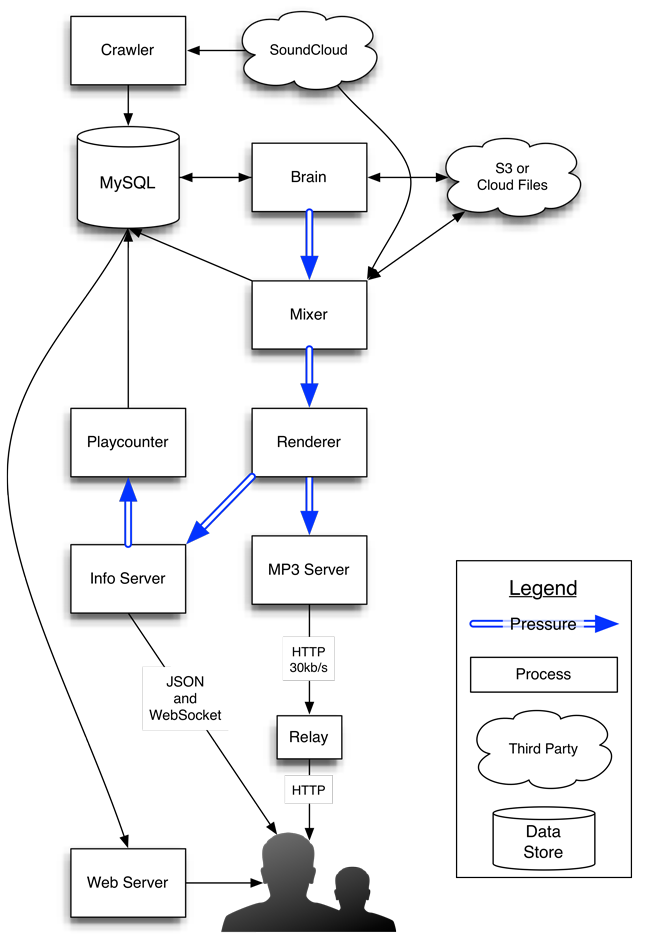
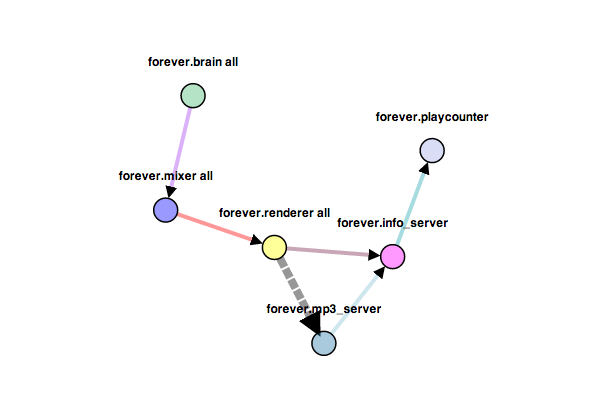
Usually, service oriented architectures are strongly request/response based, with components briefly talking with each other in short bursts. Forever does make use of this paradigm, but its central data structure is an unbounded stream of MP3 packets. As such, a lot of the app’s architecture is structured around pipelines of data of different formats. To make these pipelines reliable and fast when working with large amounts of streaming data, I constructed my own Redis-based bounded queue protocol that currently has bindings in Python and C. It also creates really nice d3 graphs of the running system:
Forever.fm is broken down into multiple services that act on these pipelines of data:
- The brain picks tracks from a traditional relational database, orders them by approximating the Traveling Salesman Problem on a graph of tracks and their similarities, and pushes them into a bounded queue.
- The mixer reads tracks from this queue in order, analyzes the tracks and calculates the best-sounding overlaps between each track and the next. This is essentially the “listening” step. These calculations also go into a bounded queue.
- The renderer reads calculations from this queue and actually renders the MP3 files into one stream, performing time stretching and volume compression as required. This step pushes MP3 frames, each roughly 23ms long, into another bounded queue.
- The mp3_server reads mp3 frames from this queue at a precise rate (38.28125 frames per second, for 44.1kHz audio) and sends them to each listener in turn over HTTP. (It also keeps track of who’s listening to help produce a detailed report of how many people heard each song.) There are a number of other services that come together to make Forever.fm work, including the excitingly-named web_server, info_server, social_server, manager, tweeter, relay and playcounter. Each of these services consists of less than 1000 lines of code, and some of them are written in vastly different languages. At the moment, they all run on the same machine - but that could easily change without downtime and without dropping the music. Each service has a different pid and memory space, making it easy to see which task is using up resources.
To help achieve an unbroken stream of music and more easily satisfy the soft real-time requirements of the app, pressure queues have two very important properties: bounds and buffers.
Each pressure queue is bounded - meaning that a producer cannot push data into a full queue, and may choose to block or poll when this situation occurs. Forever uses this property to lazily compute data as required, reducing CPU and memory usage significantly. Each data pipeline necessarily has one sink - one node that consumes data but does not produce data - which is used to limit the data processing rate. By adjusting the rate of data consumption at this sink node, the rate (and amount of work required) of the entire processing chain can be controlled extremely simply. Furthermore, in Forever, if no users are listening to a radio stream, the sink can stop consuming data from its queue - implicitly stopping all of the backend processing and reducing the CPU load to zero. By blocking on IO, we let the OS schedule all of our work for us - and I trust the OS’s scheduler to do a much better job than Python’s.
In addition, each queue has a buffer of a set size that is kept in reliable out-of-process storage - Redis, in this case. If a process were to crash for any reason, the buffer in the queueing system would allow the next process to continue processing data for some amount of time before exhausting the queue. With current parameters, nearly all of the services in Forever could fail for up to 5 minutes without causing an audio interruption. These buffers allow each component to be independently stopped, started, upgraded or debugged in production without interrupting service. (This does lead to some high-pressure bug hunting sessions where I’ll set a timer before launching GDB.)
Most of the services involved in this pipeline are backend processors of data - not front-facing web servers. However, I’ve applied the same service-oriented philosophy to the frontend of the site, creating separate servers for each general type of data served by the app. In front of all of these web servers sits nginx, being used as a fast, flexible proxy server with the ability to serve static files. HAProxy was considered, but has not yet been implemented - as nginx has all of the features needed, including live configuration reloads.
With this combination of multiple specialized processes and a reliable queuing system, Forever has enjoyed very high availability since the new architecture was deployed. I’ve personally found it indispensable to be able to iterate quickly on a live audio stream - often in production. The ability to make impactful changes on a real-time system in minutes is incredible - and although somewhat reckless at times, can be an amazing productivity boon to a tiny startup.
Partially thanks to this new architecture, I’ve also built free iOS and Android clients for forever.fm. Download them and listen to infinite radio on the go!