Using Eight Cores (incorrectly) with Python
One of my web apps, The Wub Machine, is very computationally expensive. Audio decoding, processing, encoding, and streaming, all in Python. Naturally, my first instinct was to turn to the multiprocessing module to spread the CPU-bound work across multiple processes, thus avoiding Python’s global interpreter lock.
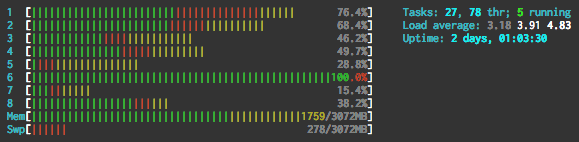
In theory, it’s simple enough, but I did run into a few very nasty problems
when dealing with multiprocessing in Python:
The multiprocessing module, at least on *nixes, forks the current process and communicates with the child with a pipe. This works wonderfully if the data you’re transferring can be easily pickled, and if the child process doesn’t need to modify any global state in the parent. Unfortunately, certain useful constructs in Python can’t be pickled, including functions and lambdas (or pretty much anything callable).
In my app, I had a peculiar use case - I would callback pass lambdas into the constructor of a class, then spawn another process on one of that class’s methods like so:
class MyClass(object): def __init__(self, my_callback): self.my_callback = my_callback def start_work(): p = multiprocessing.Process(target=self.do_work) p.start() p.join() def do_work(): # Calculate fibonacci or something, iunno self.my_callback("hey look, some data!")This lead to a baffling bug - while the callbacks were being run, their side-effects weren’t persistent. I inserted logging in the callback function to verify, and noted that not only was it running, but at the end of its execution, the global state had been set properly. However, from the perspective of the parent process, nothing had changed.
The reason was simple: the callback had been run in the child process and had modified the global state of the child process, not the parent. A simple fix would be to have eliminated these callbacks, but I instead used some of Armin Ronacher’s bad ideas in Python to create an experimental module that allows pseudo-function-calls between processes. Use (or even just read) at your own risk - it’s a hack.
Logging, the wonderful built-in Python module for meticulously logging everything, is thread-safe. Sadly, it doesn’t seem to be multiprocessing-safe. Logging makes use of its own internal I/O thread, to ensure that all log messages are properly queued and written without clobbering eachother. This thread is locked for every write.
After forking another process, the first call to the logger often hangs while waiting for the logging thread to become unlocked. If the logging thread was in use (i.e.: locked) at the exact instant the process was forked, then the locked thread will be copied to the new process. However, whatever log operation was in progress will then unlock the original thread, not the copied thread, leaving the new process to wait forever on a lock that will never be unlocked.
The solution, in my case, was to replace the logger in use with the one provided by multiprocessing if logging from a new process:
def initlog(): if multiprocessing.current_process().name == "MainProcess": _log = logging.getLogger(config.log_name) else: _log = multiprocessing.get_logger() ...
To find and fix these bugs took a lot of time, and a good debugging strategy. The most valuable tool turned out, surprisingly, to be GDB. GDB 7 has support for debugging Python runtimes, complete with pseudo-stack traces. Take a look at the following backtrace of a Python process provided by GDB and formatted for clarity:
[Thread debugging using libthread_db enabled]
[New Thread 0xb0c2fb70 (LWP 12895)]
0x006da405 in __kernel_vsyscall ()
Thread 1 (Thread 0xaf23ab70 (LWP 12894)):
#0 0x006da405 in __kernel_vsyscall ()
#1 0x003a27d5 in sem_wait@@GLIBC_2.1 ()
from /lib/i386-linux-gnu/libpthread.so.0
#2 0x080f2139 in PyThread_acquire_lock (...)
at ../Python/thread_pthread.h:309
#3 0x080f2fd8 in lock_PyThread_acquire_lock (...)
at ../Modules/threadmodule.c:52
#4 0x080da7d5 in call_function
(f=Frame 0x937b47c,
for file /usr/lib/python2.7/threading.py,
line 128,
in acquire
(self=<_RLock(...) at remote 0x9caabec>,
blocking=1,
me=-1356616848),
throwflag=0) at ../Python/ceval.c:4013
...
(goes down 79 frames)
Obviously, this looks much more complicated than a normal Python stack trace, but it’s a huge step up from zero debugability. If I proceed down a couple more frames, I find:
#7 0x080dac2a in fast_function
(f=Frame 0x9ca278c,
for file /usr/lib/python2.7/logging/__init__.py,
line 693,
in acquire (self=<FileHandler(stream=...
…which is the first piece of familiar code. Line 693 of logging/__init__.py is surrounded by a short function, and has a comment that brings the first bit of understanding:
def acquire(self):
"""
Acquire the I/O thread lock.
"""
if self.lock:
self.lock.acquire()
Well, there you go. After fixing these race conditions and deadlocks, the Wub Machine’s success rate immediately jumped from horrible to 95% under load.

All it took was GDB and an understanding of fork() to solve these bugs. My only advice: be very, very, very careful when using multiprocessing.